Cloud Data Warehouse Engineering Services: Top 5 in 2026

Updated:
May 8, 2026
Cloud data warehouse engineering services cover the full process of designing, building and operating a cloud-based data platform, from architecture and pipeline development to governance and analytics integration.
This article explains what cloud data warehousing is, how it compares to on-premises systems and data lakes, and what separates a well-executed implementation from a costly one. It also reviews the five leading platforms in 2026 – Microsoft Fabric, Databricks, Snowflake, Google BigQuery and Amazon Redshift, alongside practical guidance on choosing between in-house, outsourced and hybrid delivery models.
Whether your organisation is assessing its first cloud migration or expanding an existing platform, this guide provides an honest view of what the work involves.
What Is Cloud Data Warehousing?
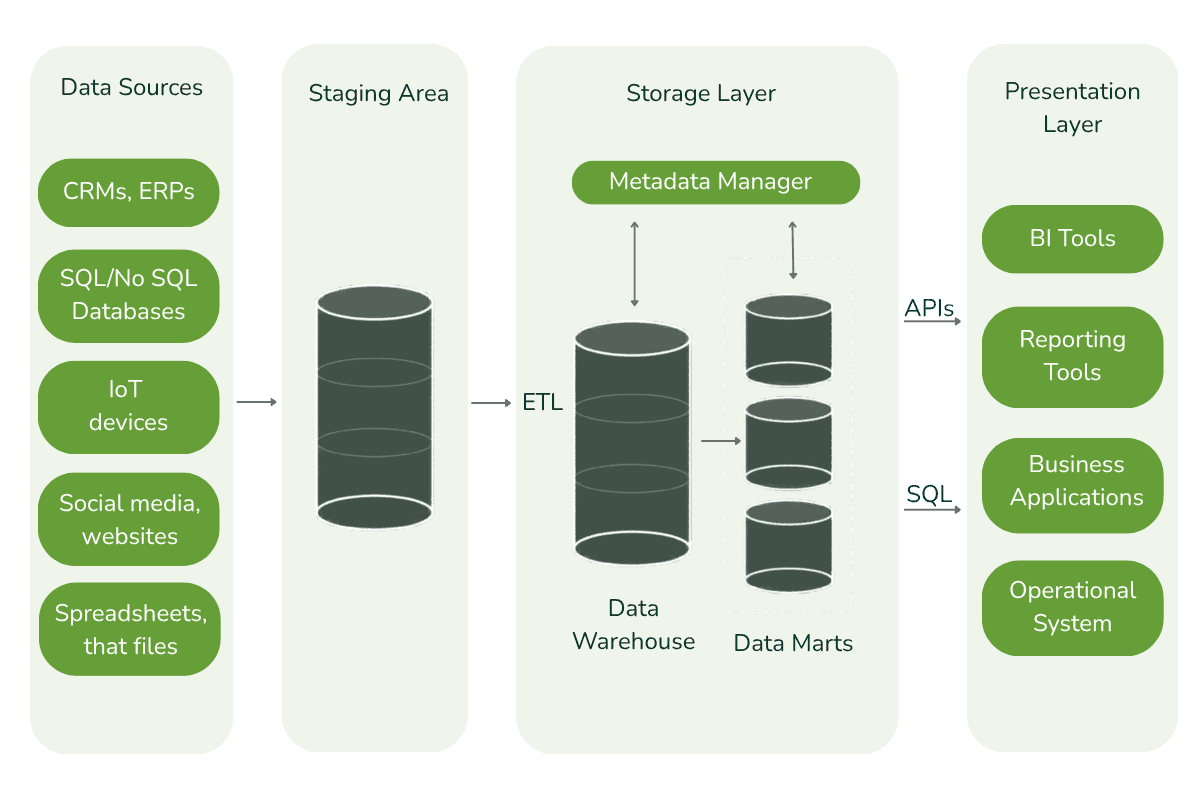
Cloud data warehousing is the practice of consolidating structured and semi-structured data from multiple source systems – CRM platforms, ERPs, spreadsheets and APIs into a single cloud-hosted repository built for analytics and reporting. Unlike operational databases designed for daily transactions, a cloud data warehouse is structured for complex queries, aggregations and historical analysis at scale.
For a detailed breakdown of the architecture and its practical advantages, the Eunoia article on the advantages of a data warehouse covers this thoroughly.
Modern implementations are cloud-native. Platforms hosted on Microsoft Azure, Amazon Web Services or Google Cloud provide elastic compute resources, which means processing power scales up or down based on workload rather than fixed hardware capacity.
A well-designed warehouse does more than mirror existing databases. It must reflect business questions, governance requirements and future analytical needs, three things that are rarely identical to what current systems were built to serve. The Eunoia guide on data warehouse strategy explores how to approach this alignment in practice.
Data Warehouse in the Cloud vs On-Premises
Traditional on-premises warehouses require organisations to purchase and maintain hardware. Capacity planning is fixed, and scaling typically involves significant capital expenditure with long procurement timelines.
Cloud platforms change that equation in four practical ways.
- Elastic scalability. Platforms such as Azure Synapse Analytics, Snowflake and Google BigQuery allow compute resources to increase during reporting cycles and reduce during quieter periods, charged by usage, not by installed capacity.
- Reduced infrastructure maintenance. Cloud providers manage the underlying hardware, patching and performance tuning, freeing internal teams from operational overhead that adds no analytical value.
- Flexible cost structures. Pay-as-you-go pricing, when combined with good engineering practices, often reduces long-term operational cost compared to permanently provisioned infrastructure. That said, poorly designed platforms can see cloud costs rise quickly (more on this below).
- Easier integration. Cloud warehouses connect naturally with APIs, SaaS tools and cloud storage, making it practical to bring data from across the modern software stack into one place.
For organisations assessing their current data readiness before committing to a cloud platform, Eunoia’s data readiness assessment is a useful starting point.
Cloud Data Warehouse vs Cloud Data Lake
Data warehouses and data lakes are often treated as alternatives, but they serve different purposes and suit different workloads. Understanding the distinction matters when choosing an architecture.
A data warehouse stores structured, curated data organised in predefined schemas. This makes it well suited for business intelligence reporting, financial analytics and regulatory compliance – workloads where consistency and query speed are priorities.
A data lake stores raw data in its original format. It handles structured, semi-structured and unstructured content such as logs, text files, images, and applies structure at the point of query rather than at ingestion. This gives data science teams more flexibility for experimentation and machine learning work.
The technical distinction is often framed as schema-on-write versus schema-on-read. Warehouses transform and validate data before loading it. Lakes store first and transform when needed.
A newer architecture, the lakehouse, combines both approaches in a single environment. Databricks is one of the leading platforms for this model, supporting traditional BI workloads alongside machine learning pipelines within the same infrastructure. Eunoia’s article on data lakehouse vs data warehouse covers the trade-offs in depth.
What Are Cloud Data Warehouse Engineering Services?
Cloud data warehouse engineering services cover the full lifecycle of designing, building and operating a modern data platform, from initial architecture through to live analytics environments. This includes pipeline development, data modelling, governance, security and ongoing operational support. Eunoia’s data engineering services page outlines the full scope, which typically includes the following.
- Architecture design. Selecting the right platform and defining how data will be ingested, stored, transformed and served to analytics tools.
- Data pipelines. Building automated pipelines that extract data from source systems, apply transformations and load structured data into the warehouse.
- Data modelling. Designing data models that reflect business concepts, align metric definitions across departments and support reporting requirements.
- Governance and security. Implementing access controls, encryption, data lineage tracking and compliance processes. This work is foundational, not optional.
- Analytics integration. Connecting BI tools such as Microsoft Power BI so business teams can build dashboards and self-service reports against reliable, well-structured data.
- Operational support. Monitoring platform performance, controlling costs and maintaining data quality as the environment grows and new sources are added.
The Most Common Early Mistake
From our team’s experience, one of the most frequent problems in data platform projects occurs before any pipeline or architecture work begins. Organisations consistently underestimate the data exploration required to understand their existing systems.
Source systems that appear straightforward from a user interface perspective often contain significant complexity underneath – inconsistent data types, historical anomalies, undocumented business logic and fragmented schemas. Without exploring the underlying data estate in detail, these issues surface during integration, causing delays and redesigns that could have been avoided.
A second, related challenge is defining business KPIs around the limitations of existing systems rather than the organisation’s actual analytical goals. Effective data strategy requires separating what current systems can produce from what the business genuinely needs. Clear alignment between business ambition and technical reality helps organisations avoid surprises mid-project.
Building a Single Version of the Truth
One of the most important outcomes a cloud data warehouse delivers is a shared, consistent view of organisational data. When finance, operations and leadership rely on different data definitions, trust in reporting quickly erodes.
Consolidating data into a single platform and aligning metric definitions across departments means everyone works from the same numbers. Once that alignment exists, data quality questions become easier to investigate because there is a shared understanding of what each metric represents.
Supporting this with a data glossary, a defined vocabulary for business users, further improves consistency, particularly as self-service analytics adoption grows. Eunoia’s article on self-service data analytics discusses the conditions that make this work in practice.
Controlling Cloud Costs
Cloud platforms charge by usage, often by the minute. Without careful planning around compute capacity, redundancy strategies, networking and storage configuration, infrastructure costs can rise faster than expected.
Effective cost management begins before a line of code is written. It involves selecting appropriate resource configurations, designing with efficiency in mind from the outset and applying established best practices at the architecture level. Decisions made early about data partitioning, compute clustering and pipeline scheduling have a direct and lasting effect on monthly cloud spend.
Best 5 Cloud Data Warehouse Solutions in 2026
The following platforms represent the current leading options for cloud data warehouse engineering. Each has distinct strengths and is suited to different organisational contexts.
1. Microsoft Azure Synapse Analytics and Microsoft Fabric
Microsoft Fabric integrates data engineering, warehousing, real-time analytics and business intelligence within a single platform. Its OneLake architecture provides a unified storage layer designed to reduce duplication and simplify data management across departments.
Combined with Azure Synapse Analytics, organisations gain a scalable cloud warehouse capable of supporting complex analytics and enterprise reporting. The tight integration with the Microsoft ecosystem, including Power BI, Teams and the wider Azure services portfolio, makes this the natural choice for organisations already standardised on Microsoft technology.
For a detailed view of what Fabric offers and where it fits in a modern data stack, Eunoia’s article on the benefits of Microsoft Fabric is worth reading alongside this overview.
2. Databricks Lakehouse Platform
The Databricks Lakehouse Platform combines data lake storage with warehouse-style governance and query performance in a single architecture. This approach supports both traditional BI workloads and machine learning pipelines, making it particularly strong for organisations working with large-scale analytics, AI models or streaming data.
Databricks is often adopted by organisations whose analytical requirements go beyond standard reporting – teams building predictive models, running real-time data processing or managing large, heterogeneous datasets across multiple domains.
3. Snowflake
Snowflake is a cloud-native data warehouse built around a separation of compute and storage. This architecture allows independent scaling of each layer, which translates to efficient workload management and predictable cost control for structured analytics.
Snowflake is widely used for financial reporting, cross-team data sharing and business intelligence workloads. Its data marketplace features also allow organisations to access and share external datasets, which can be valuable in sectors such as finance and logistics where third-party data enrichment is common.
4. GoogleBigQuery
Google BigQuery is a serverless data warehouse built for large-scale analytical queries. Its architecture removes the need for infrastructure provisioning, allowing teams to focus entirely on analytics rather than platform management.
BigQuery integrates directly with the broader Google Cloud ecosystem, including its machine learning services, data processing tools and Looker for business intelligence. It is a strong option for organisations already operating within Google Cloud or working with large volumes of public datasets.
5. Amazon Redshift
Amazon Redshift is a mature cloud data warehouse within the AWS ecosystem. It supports large-scale analytical queries and integrates closely with other AWS services, S3, Glue, Lambda and SageMaker among them, making it a practical choice for organisations whose infrastructure is already built on AWS.
Redshift has evolved significantly in recent years, adding serverless options and improved integration with data lake storage, which has extended its relevance for organisations managing both structured and semi-structured data.
Implementation Options: In-House, Outsourced or Hybrid?
Organisations typically adopt one of three delivery models when implementing a cloud data warehouse. The right choice depends on internal expertise, timeline pressures and the complexity of the existing data environment — particularly where cloud data migration from legacy systems is involved.
In-House Implementation
Internal engineering teams design and maintain the platform. This offers full control over architecture decisions and allows the team to build deep knowledge of the data environment. The trade-off is that it requires strong existing expertise in data engineering, cloud architecture and governance — skills that are genuinely difficult to hire for now.
In-house delivery also tends to move more slowly in the early stages, particularly when teams are learning new platforms alongside delivery commitments.
Outsourced Cloud Data Warehouse Engineering Services
Specialist firms take responsibility for architecture design, cloud data migration planning and platform implementation. This reduces technical risk and typically accelerates delivery, particularly in the critical early phases where architectural decisions have the longest-lasting consequences.
From a client project perspective, organisations that bring in external expertise at the architecture stage — rather than after the first design has run into problems — tend to avoid the costliest rework. Eunoia’s legacy system migration case study for Hudson Holdings Group illustrates how this plays out in practice.
The organisational dimension of migration is often underestimated. New platforms introduce different workflows, governance processes and decision-making structures. Successful projects invest in internal champions – people within the business who understand the new approach and can advocate for adoption across departments.
Hybrid Models
Many organisations combine external expertise with internal teams. External engineers build the foundation and introduce best practices while internal staff gradually develop ownership of the platform. This model works well when the goal is long-term self-sufficiency rather than permanent dependency on external support.
Eunoia’s engagement with RightShip demonstrates this hybrid approach, where external data engineering expertise was applied to a complex operational environment, with a clear focus on building internal capability alongside delivery.
From our team’s experience, technical maturity matters as much as business requirements when selecting a delivery model. Deploying a complex lakehouse architecture without the internal capability to manage it can increase costs through inefficient compute usage, poorly configured pipelines and over-engineered data flows. For many organisations, beginning with a well-structured data warehouse and expanding gradually is the more practical path.
Key Benefits of Cloud Data Warehousing
A properly engineered cloud data warehouse consolidates data from across an organisation into a single reliable platform — replacing fragmented systems, manual reporting and inconsistent metrics with a shared, trusted foundation for decision-making. For finance, insurance and other regulated sectors, the governance and compliance capabilities are particularly significant. Eunoia’s work in financial services data and AI illustrates how these benefits apply in practice. A fuller treatment is available in the Eunoia article on the advantages of a data warehouse.
- Unified data environment. Data from multiple systems is consolidated into one platform, producing consistent definitions and a single shared view of organisational performance.
- Faster reporting.Automated pipelines replace manual data consolidation processes. Reports that previously took days can be produced in minutes.
- Improved data quality.Structured transformation and validation processes reduce inaccuracies and inconsistencies that accumulate in fragmented systems.
- Scalable infrastructure.Cloud platforms handle increasing data volumes and user concurrency without major architectural changes.
- Governance and compliance. Role-based permissions, audit logs and encryption support regulatory requirements, critical for organisations in finance, insurance and other regulated sectors.
- AI readiness. When a platform captures detailed, granular data over time, it forms a strong foundation for predictive modelling and machine learning.
Building an AI-Ready Data Platform
Artificial intelligence projects frequently stall when the data foundation beneath them is inadequate. The guiding principle for AI readiness is straightforward: collect and retain as much relevant data as possible, at the most granular level available, over time.
Modern data formats and compression technologies have significantly reduced the cost of retaining large datasets. The risk of storing too much is now far lower than it once was. Organisations that maintain detailed historical records are in a much stronger position to build predictive models at varying levels of granularity when new analytical questions arise — rather than discovering, after the fact, that the data they need was never captured.
For a practical view of how Eunoia approaches data modernisation, the article on practical steps for data modernisation covers the sequencing and priorities that tend to produce reliable outcomes.
Measuring Whether a Platform Is Delivering Value
After a cloud data warehouse goes live, value is rarely demonstrated through technical metrics alone. The more useful indicators are behavioural. How frequently do business teams access the platform? Are users requesting further enhancements — which suggests the environment has become genuinely useful rather than tolerated? Is direct feedback from users positive about reliability and analytical value?
When teams regularly rely on the platform and ask for more, the architecture has become part of how the organisation makes decisions. That is the goal.
Build the Foundation Correctly
Cloud data warehouses are now central to how mid-to-large organisations manage their data. They consolidate fragmented systems, produce consistent reporting and provide the infrastructure required for advanced analytics and machine learning.
But technology alone does not determine outcomes. From our team’s experience across finance, maritime and enterprise services, the organisations that get the most from their data platforms share a few common characteristics. They invest time in understanding their existing data before engineering begins. They align governance and business definitions early. They choose architecture based on their actual technical maturity, not on what sounds most impressive.
The right platform, implemented with the right approach, does not need to be the most complex one. It needs to be the one the organisation can operate, maintain and build on reliably. As the Eunoia article on data modernisation puts it — the foundations matter more than the features.
Ready to Build a Cloud Data Platform?
Most data platform projects fail because of the architecture was chosen without fully understanding the data, the governance was an afterthought, or the scope was not realistic from the start.
Eunoia’s team of data engineers and architects has delivered cloud data platforms across several verticals, assisting organisations at every stage, from initial assessment through to full production.
Not sure where your data platform stands?
Take Eunoia’s self-assessment to see how ready your data is for a cloud warehouse.
Ready to start building?
Speak to the Eunoia team about your architecture, platform choice, or migration.
See how we helped others
We built cloud data platforms for multiple different verticals. Check our case studies.


Frequently Asked Questions
What is cloud data warehousing?
Cloud data warehousing is the practice of hosting a centralised analytical data repository on cloud infrastructure, rather than on-premises hardware. The warehouse consolidates data from multiple source systems, applies structure and governance, and makes it available for business intelligence, reporting and analytics. Cloud hosting adds elastic scaling, managed infrastructure and usage-based pricing compared to traditional on-premises approaches.
What is an example of a cloud data warehouse?
What are the four types of cloud services?
What skills are needed for cloud data warehouse engineering?
What is the difference between a data warehouse and a data lakehouse?
How much do cloud data warehouse engineering services cost?
Isaac Zammit, Chief Technology Officer
Author
Isaac Zammit is Chief Technology Officer at Eunoia Data & AI. He leads data strategy consulting for CEOs and executive teams who are tired of AI pilots that never reach production.